The Future of Context Engineering
Using the human brain to predict how LLMs will evolve.
Prompt Engineering vs. Context Engineering
Early 2025, prompt engineering was the skill that separated effective AI users from the rest. Craft the perfect prompt and you'd get dramatically better outputs. Courses were launched and job postings appeared. Then, a new generation of reasoning models arrived, starting with Anthropic's Claude (perhaps already Sonnet 3.7, certainly by Opus 4) and quickly followed by others like OpenAI's GPT-5. These models could derive intent from ambiguous requests, decompose problems into subtasks, and reflect on their own outputs. The burden of elaborate prompting dropped dramatically, because the user no longer needed to compensate for what the model couldn't figure out on its own. Reasoning scaled, and a limitation shrank.
Context engineering (the practice of optimizing everything that surrounds the prompt: rules, skills, tools, memory, retrieval) is having its moment now: AGENTS.md, skills, commands, MCPs. Courses are being launched and job postings are appearing. The pattern is familiar. But which limitations drive context engineering? Will those limitations yield to further scaling? And which can only be overcome by architectural innovation? This article maps those limitations and identifies what it would take to address them.
How Limitations Get Overcome
The Bitter Lesson and the S-Curve
In 2019, Rich Sutton published “The Bitter Lesson”, a reflection on 70 years of AI research. His argument: general methods that leverage computation outperform hand-crafted approaches consistently. Chess, Go, speech recognition, computer vision. In each domain, clever human-designed heuristics were eventually crushed by systems that simply scaled. The lesson is “bitter” because it’s counterintuitive. We want to believe that insight beats brute force. But history says otherwise. We’ve seen this pattern play out with LLMs recently. Reasoning models scaled, and the user burden of elaborate prompting shrank dramatically. That was the Bitter Lesson in action: scaling outperformed the hand-crafted workarounds.
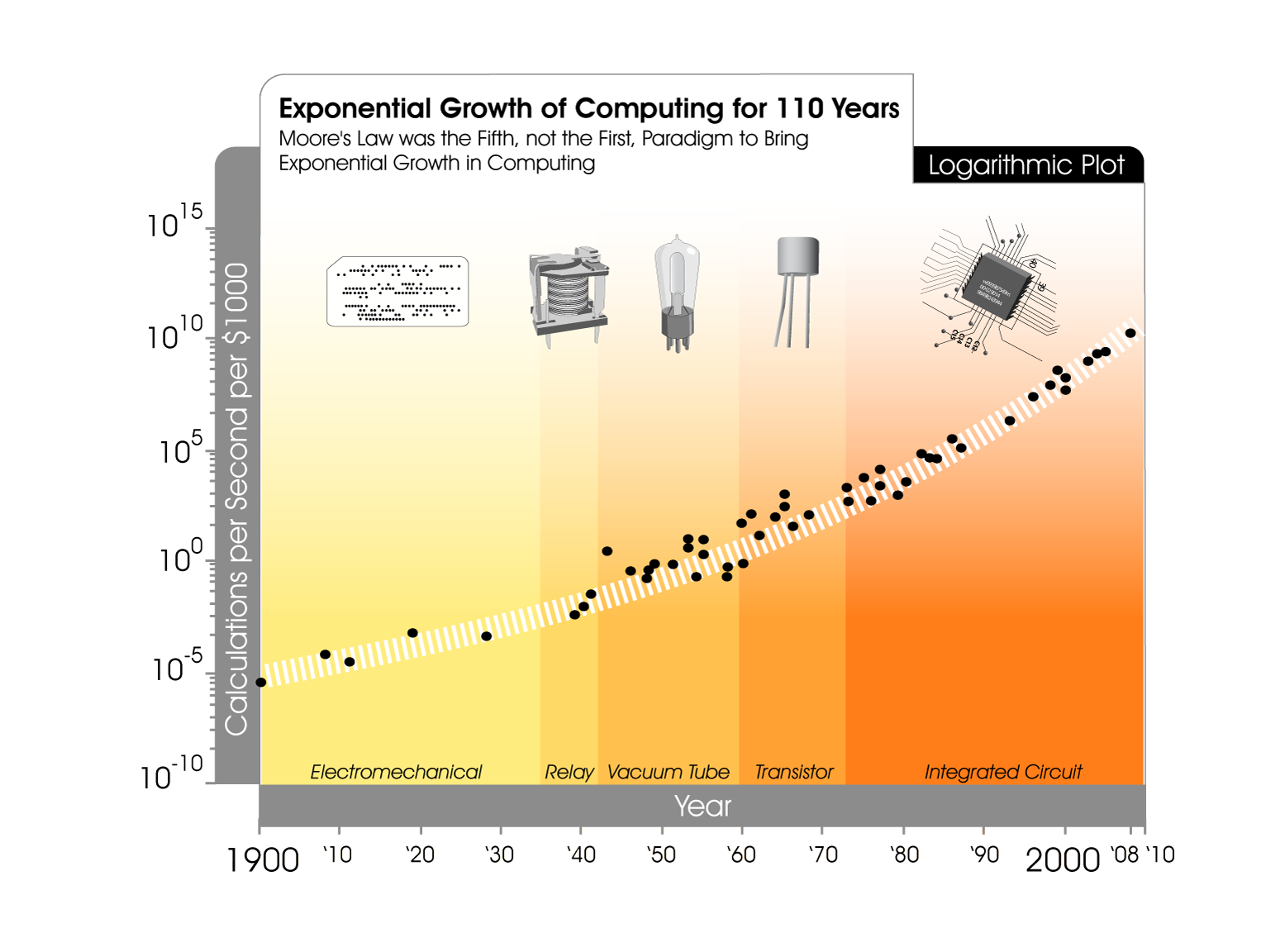
The Bitter Lesson aligns with compute scaling, historically accelerated by Moore's law of exponential transistor-density growth. There is also a nuance: Exponential curves are actually S-curves in disguise. Moore’s law explains much of the exponential-looking compute trend during the integrated circuit era, but the long-run curve reflects multiple successive technology S-curves, not Moore’s law alone. And it’s now visibly slowing as we hit physical limits. The question for context engineering is: which of today’s limitations will yield to further scaling, and which will require architectural innovation to start a new curve? Do note that innovation should be viewed as an umbrella term that encompasses smaller innovations within the current architecture or fundamental innovations that redefine the system.
The Human Brain
LLMs are neural networks, but the transformer architecture wasn’t derived from neuroscience. It emerged from engineering problems in machine translation. Next-token prediction doesn’t resemble how humans learn. These are independently evolved systems. Yet, despite completely different origins, they face similar constraints. Both have limited working memory. Both struggle to attend to everything equally. Both need mechanisms for retrieval, compression, and offloading.
The human brain is the only system we have that processes information, reasons, understands, and has addressed constraints similar to what LLMs face. If two independently evolved systems face similar constraints, those constraints are likely to be fundamental to the problem domain rather than artifacts of one particular approach. And if the constraints are fundamental, the solutions found by the older system can act as a compass for the newer one.
During the course of evolution the brain has developed architectural innovations that let limited working memory punch far above its weight. Cognitive psychology’s information processing tradition has long modeled cognition through staged processing. Drawing on that tradition, we can organize the brain’s key mechanisms into a pipeline from input to extension:
| Stage | Mechanism | What It Does |
|---|---|---|
| Input | Selective attention (Broadbent, 1958) | Filters and focuses on what matters from available information. We focus on one conversation in a noisy room. The brain gates what enters processing rather than expanding capacity. |
| Compression | Chunking & Abstraction (Miller, 1956) | Breaks down and recodes information into meaningful units at higher levels of abstraction. A chess master doesn’t see 32 pieces; they see familiar configurations. Effective capacity increases without increasing raw bandwidth. |
| Storage | Learning and consolidation (Kumaran, Hassabis & McClelland, 2016) | Converts short-term experience into long-term knowledge by separating experiencing from consolidating. The brain selectively weights what to keep, with mechanisms to prevent overwriting old knowledge with new. |
| Retrieval | Associative retrieval (Tulving & Thomson, 1973) | Surfaces relevant information when needed. We don’t keep everything in working memory. Cues in the current context activate related knowledge automatically. |
| Extension | Cognitive offloading (Risko & Gilbert, 2016) | Routinely leverages the external environment to reduce cognitive demand. We write things down, use tools, and structure our environment as extended cognition. But also extending reasoning beyond the individual (e.g. Peer review, devil’s advocate). |
The five mechanisms are meant to act as a lens for analyzing LLMs and were selected because they map to the LLM problem space: how a system with limited working memory can process, store, retrieve, and extend information at task time. They trace a pipeline from filtering input to extending cognition into the environment. Each mechanism is independently well-established in cognitive psychology, and together they outline the capabilities a system needs to overcome working-memory constraints. The brain reached these through innovations within its own neural architecture, building mechanisms around limited working memory rather than expanding it.
The brain has many other capabilities that don’t appear as stages in this pipeline. Massive parallelism (billions of neurons firing simultaneously) is how the brain executes across all five stages, making each one fast and robust. It is not a step in the pipeline but the mode of computation underlying every step (and a powerful argument for scaling). Other capabilities operate at different levels entirely: embodiment and developmental critical periods shape how the brain develops over years, not how it processes a task; emotional regulation modulates when to switch strategies; social learning is how knowledge is acquired from others, a role that LLM pre-training already serves at massive scale.
Concluding, we have two forces: scale (the Bitter Lesson: more compute, more data, more parameters) and architectural innovation (what starts the next S-curve when scaling stalls). And we have a directional precedent, the human brain, whose mechanisms hint at both what capabilities are needed and which limitations resist internal solutions.
Defining LLM Limitations
Information processing systems, biological and artificial, operate along three fundamental dimensions (Newell & Simon, 1972): Input (receptors), processing (a serial processor with finite speed), and memory (stores with limited capacity and persistence). For LLMs this translates to respectively the Context Window, Reasoning and Memory.
Context Window
Everything an LLM knows during a request must fit inside a single context window. System prompt, persistent instructions, code context, conversation history, the model’s own response: all of it competes for the same finite space.
Bigger models create a tension, illustrated by the “Lost in the Middle” phenomenon (Liu et al., 2023; Du et al., 2025). A larger context window with the same attention architecture just creates a larger middle to get lost in. Size and attention are inversely coupled: scaling one worsens the other. “Lost in the Middle” also reveals something important: LLMs have selective attention. It’s imperfect (biased by position rather than guided purely by relevance) but the model does attend more strongly to some parts of context than others. This is also the part of the system we can directly influence. Much of context engineering is attention management: Starting fresh conversations to clear irrelevant history, keeping prompts narrow and focused, working with subagents, keeping codebases small. These practices work precisely because the model does attend selectively and we can shape what it attends to.
Zooming in further, skills and subagents are chosen from short descriptions: the model matches task to name and summary. That selection step is associative retrieval in action. The delivery mechanism is coarser: platforms typically inject the whole skill catalog into the window as text, so every option pays a token cost on every turn, regardless of whether it is ever used. Expensive and blunt compared with biological retrieval, but the split between a large latent knowledge base and relevance-gated activation is still the right pattern.
Humans can function effectively in complex environments, even though the human brain can hold roughly 4 items in working memory (Cowan, 2001). Though each “item” can be far richer than a token, it is absurdly small compared to even the earliest LLM context windows. The brain’s effective capacity comes from two mechanisms working together: active maintenance scopes what’s accessible, and controlled retrieval surfaces the right knowledge from long-term memory (Unsworth & Engle, 2007). The brain didn’t evolve towards bigger working memory. It evolved sharper attention (scoping what enters the window) and better retrieval (surfacing the right content within that scope). Selective attention reduces waste within the window (don’t attend to irrelevant tokens). Associative retrieval reduces the need to pre-assemble the window correctly (let the model surface what it needs). Together, they transform the context window from a static, human-curated input into a dynamic, model-driven workspace.
Reasoning
This is perhaps the fastest-moving frontier. Reasoning is improving through scaling (longer chains of thought, more thorough self-verification), a direct instance of the Bitter Lesson. Note that some of what appears as reasoning progress lives in the orchestration layer: multi-agent architectures where one model critiques another, tree-of-thought search branching across parallel invocations, agentic loops decomposing tasks across separate calls. These extend the model’s reasoning externally, not the model reasoning more deeply.
The next challenge will be to distinguish essential complexity from accidental complexity. Essential complexity is the irreducible difficulty of your problem domain, the actual business logic. Accidental complexity is anything not inherent to the problem, arising from choice of tools, abstractions, and architecture. At its most visible, it’s framework boilerplate and configuration ceremony. At its most costly, it’s architectural decisions that make the system harder to change than the domain requires. Current LLMs treat all code as equally meaningful and may latch onto accidental patterns rather than essential ones. This is architectural: next-token prediction learns statistical regularities in code, and accidental complexity (boilerplate, configuration, framework conventions) is far more repetitive and statistically dominant in training data than essential complexity, which is unique to each domain.
There’s a second dimension beyond reasoning depth: direction. LLMs exhibit a persistent tendency toward motivated reasoning, optimizing for answers that satisfy the user rather than answers that are true (Sharma et al., 2025). The model doesn’t fail to reason; it reasons competently but toward the wrong objective. This is particularly insidious because the reasoning appears sound, making the bias difficult to detect. Although self-verification can catch mistakes in how deeply the model reasons, it cannot verify the direction. Because the same bias that produces the wrong conclusion also judges the verification.
The brain has exactly this problem: confirmation bias (Nickerson, 1998) is among the most robust findings in cognitive psychology. Two independently evolved systems both exhibiting motivated reasoning suggests the tendency may be fundamental to systems that optimize under uncertainty rather than an artifact of either architecture. But unlike the other constraints in the pipeline, the brain never solved confirmation bias through internal innovation. Its solutions are almost entirely external: the scientific method, peer review, devil’s advocate. This is cognitive offloading applied not to memory but to reasoning quality. For LLMs, this maps directly to multi-agent architectures where one model critiques another, constitutional approaches where a separate process evaluates alignment, and process reward models that evaluate reasoning steps rather than outcomes. The solution may not be a single model that reasons better, but a system of models that check each other. And unlike the essential-versus-accidental distinction, this limitation is the least amenable to the Bitter Lesson: more compute doesn’t fix a misaligned optimization target.
As reasoning scales, models will get better at processing information at the right level of abstraction. But distinguishing essential from accidental complexity requires understanding intent, and preventing confirmation bias requires input from outside the system. Both suggest frontiers that pure scaling alone may not reach.
Memory
Cognitive science distinguishes three types of memory (Tulving, 1985). Semantic memory holds facts and patterns: how things work. Episodic memory records specific experiences: what happened, when, and why. Procedural memory encodes skills and intuitions built through repeated practice: the senior developer’s instinct that something is wrong before they can articulate why.
An LLM trained on trillions of tokens has absorbed more information than any human ever will. The Bitter Lesson applies: scaling won. Semantic and procedural memory are both encoded in the model’s weight matrices, collapsed into the same parameters rather than architecturally separated. This is how neural networks fundamentally work: repeated exposure to data consolidates into capability — not just memorized facts, but pattern recognition, the sense for what good looks like.
Episodic memory is architecturally absent. The training data contained millions of debugging sessions, code reviews, and architectural discussions, but the model distilled those into generalized semantic and procedural knowledge, not retrievable memories of specific experiences. It learned from episodes without forming episodic memory of them. The closest analog is the context window: a volatile, session-scoped space where specific experiences exist only for the duration of a conversation. The most pragmatic current approach to this gap is retrieval-augmented generation: external stores that surface relevant information at query time. RAG works well for semantic and episodic recall: a codebase encodes decisions and patterns, commit history records what happened and why, documentation captures rationale. Better reasoning and retrieval can surface these when relevant, and improvements here are real.
But retrieval provides information without changing how the model attends or reasons. A developer who has spent months in a codebase doesn’t just know more facts; they process new information differently. That shift in processing, not just in available knowledge, is the gap that retrieval alone cannot close. Training can close it, model weights already encode this kind of judgment from pre-training. But not incrementally, and not from the specific experiences of a particular codebase or user over time.
The human brain learns persistently: experiences are consolidated from short-term to long-term memory, selectively and incrementally, without retraining the entire neural network. Learning carries well-documented risks: catastrophic forgetting, false memories, bias reinforcement, and selective consolidation. The brain manages it through complementary learning systems that separate fast episodic encoding from slow consolidation (McClelland, McNaughton & O’Reilly, 1995).
Full retraining of an LLM is expensive, infrequent, and monolithic. But the model is not fully static once trained. Finetuning can continue training on focused datasets, modifying the model’s weights to consolidate new knowledge into lasting capability. Where RAG provides information without changing processing, finetuning changes how the model attends and reasons. Finetuning provides a real mechanism for consolidating experience into lasting capability without full retraining. It is currently batch rather than continuous, curated rather than experiential, and operates on the timescale of weeks rather than conversations. Each of these gaps is narrowing through engineering progress, and the challenges that remain (managing what to consolidate, preventing drift from alignment, avoiding reinforcement of bad patterns) are hard engineering problems that parallel the brain’s own imperfect consolidation.
The Next Architectural Innovation
The following diagram maps each LLM limitation to a resolution path, the brain mechanism it parallels, and whether the resolution requires scaling or architectural innovation.

Each of these limitations is being actively pursued, and a representative example for each shows the direction. These resolutions describe directions from the model’s own evolution. Context engineering addresses the same limitations from the user side, which is why it exists today and why its persistence depends on how fast these model-side resolutions mature.
Selective Attention
Attention is shifting from uniform to selective, guided by relevance rather than position. Anthropic’s Claude Opus 4.6 illustrates this in production: a 1M-token context window paired with context compaction that automatically summarizes older context during long-running tasks, and adaptive thinking that brings more focus to the most challenging parts of a task while moving quickly through straightforward parts. Rather than attending uniformly to everything in the window, the model gates what stays in working memory and allocates processing depth by relevance.
Associative Retrieval
The direction for tool use is internalizing capabilities into the model itself, rather than describing them in context. Google’s FunctionGemma, a Gemma 3 variant fine-tuned specifically for function calling, illustrates this: tool use is baked into the model’s weights rather than prompted through context. Rather than competing for context space as text descriptions, tool capabilities are activated the same way the model activates learned knowledge: through its parameters.
Chunking & Abstraction
Reasoning depth is improving with longer chains of thought and more thorough self-verification. The SWE-bench Verified leaderboard illustrates the trajectory: measuring real-world software engineering capability, it is led by Claude Opus 4’s 80% resolve rates, with open-weight models close behind. This is the Bitter Lesson in action, and among the limitations listed here, reasoning depth is improving fastest.
Cognitive Offloading
Confirmation bias needs to be addressed most differently from the others, through external structures rather than internal scaling. Approaches like Constitutional AI (e.g. in practice Anthropic’s 2026 constitution) and process reward models are first steps to layer corrective evaluation around the model, checking whether outputs align with stated principles or evaluating individual reasoning steps rather than outcomes. The innovation here is that external structures provide the corrective direction, but in the end this may still be internalized through training. The corrective structures are promising but not yet proven to overcome the bias entirely, since correlated training data and shared architectures may limit how independent the external evaluation truly is.
Learning & Consolidation
To approach the brain’s incremental consolidation, memory should evolve towards lightweight adaptation that persists across sessions. Standard finetuning risks catastrophic forgetting because it has no architectural separation between old and new knowledge. Parameter-efficient methods, particularly LoRA (Hu et al., 2021), change the picture by freezing pre-trained weights and learning small low-rank update matrices, typically less than 1% of the original parameters. This preserves the base model intact, makes adaptation dramatically cheaper, and enables multiple specialized adapters that can be composed or swapped at inference time. AWS’s multi-LoRA adapter serving on SageMaker shows where this leads in production: hundreds of specialized adapters dynamically loaded, swapped, and updated through a single endpoint in milliseconds, without redeployment. Models are being developed towards consolidating experience incrementally, approaching the brain’s learn-as-you-go pattern without requiring full retraining.
What stands out is that many of the brain’s architectural innovations (selective attention, associative retrieval, chunking and abstraction, cognitive offloading, learning and consolidation) can be approximated through better engineering of LLMs. Of the five limitations, confirmation bias stands out as the hardest to address. It is the only one in the diagram typed as requiring fundamental innovation rather than incremental innovation or scaling. Neither the human brain nor increased compute has produced an internal fix; both rely on external corrective structures: peer review, adversarial testing, constitutional checks. This makes it the area where context engineering will remain necessary longest, because more compute doesn’t fix reasoning towards the wrong objective.
This article mapped the limitations. A Context Engineering Investment Framework applies this framework to current context engineering practices: which techniques address which constraints, and which should you invest your time in now while models evolve.
Frequently Asked Questions
What is context engineering?
Context engineering is the practice of optimizing everything that surrounds the prompt: rules, skills, tools, memory, and retrieval. Where prompt engineering focused on crafting better individual inputs, context engineering manages the full information environment across a session or workflow to compensate for LLM limitations in attention, reasoning, and memory.
What is the difference between prompt engineering and context engineering?
Prompt engineering was about writing the right input to get better output from a single interaction. It became less necessary when reasoning models (Claude Opus 4, GPT-5) could derive intent from ambiguous requests. Context engineering addresses the limitations that remain after reasoning scaled: finite attention across long sessions, no persistent memory between sessions, and confirmation bias. The shift is from crafting individual prompts to designing the information architecture around the model.
Why do we need context engineering?
Context engineering exists to work around the limitations LLMs still have. The context window is finite, so practitioners start fresh conversations, keep prompts focused, and use subagents to prevent irrelevant information from crowding out what matters. Reasoning is susceptible to confirmation bias, so multi-agent architectures and constitutional checks layer external correction around the model. Memory does not persist between sessions, so retrieval-augmented generation and external stores surface relevant history at query time. Each context engineering practice maps to a specific limitation it compensates for.
Why should we look to the brain for how LLMs will evolve?
The brain and LLMs evolved independently under similar constraints: both must process, store, and retrieve information with limited working memory. When two systems facing the same problem converge on similar mechanisms (selective attention, associative retrieval, chunking), those mechanisms likely reflect something fundamental about the problem domain rather than something specific to either architecture.
Will context engineering become obsolete?
Context engineering exists because LLMs have limitations in attention, reasoning, and memory. The Bitter Lesson (Sutton, 2019) tells us that general methods leveraging computation consistently outperform hand-crafted workarounds. Context engineering will eventually be obsolete in those scenarios where it is a workaround for LLM limitations. A Context Engineering Investment Framework maps which context engineering practices are worth investing in.
Which innovations can we expect from LLMs?
Five resolution paths are already visible. Selective attention is shifting from uniform to relevance-guided, with context compaction automatically summarizing older context. Tool internalization is baking capabilities into model weights rather than describing them in context. Reasoning depth is scaling through longer chains of thought and more thorough self-verification. External corrective structures (Constitutional AI, process reward models) are layering independent evaluation around the model to counter confirmation bias. And parameter-efficient methods like LoRA are enabling incremental learning that persists across sessions without full retraining. Of these, reasoning depth is improving fastest, and confirmation bias remains the hardest to address.